A new benchmark for LLM SVG performance
We’re excited to share something we’ve been working on at Presto Design — a public benchmark to help AI models get better at graphic design. Why? Because the world doesn’t just run on text and numbers. We all crave creativity, visuals, and designs that make things look and feel great. If AI is going to be a useful tool for designers, it needs to truly understand and generate beautiful, structured graphics.
Download the Benchmark
Want to try it out? Grab the dataset here:
https://huggingface.co/datasets/Presto-Design/svg_basic_benchmark_v0
If you’re more of a hands-on person, you can run the benchmark yourself with our GitHub repo:
https://github.com/Presto-design/svg-benchmark
Why Graphic Design Matters
Graphic design is everywhere — from the apps we use to the posters we walk past, to the way businesses communicate their brands. It’s not just about looking good; it’s about storytelling, emotions, and making things more engaging. AI is great at working with words, but it needs to step up its game when it comes to visuals.
Can LLMs Help With Graphic Design?
Large Language Models (LLMs) are starting to play a big role in graphic design. They can work with branded assets, pick out the right stock photos, match fonts, and create scalable designs that work across different formats. These are things that models like Stable Diffusion struggle with.
But here’s the problem: LLMs still suck at design. People have been sharing their frustrations online — failed attempts, weird layouts, and AI-generated graphics that just don’t make sense.
Check out https://lunary.ai/blog/llms-and-svgs:


How Presto is Pushing AI Graphic Design Forward
We’re diving deep into this challenge. Our goal is to push LLMs to actually get better at design, not just spit out random SVG code. And that’s where this benchmark comes in.
What’s in the Benchmark?
This dataset has 2,000 images paired with their SVG code, testing a wide range of design elements, like:

- Colors
- Shapes
- Images
- Masks
- Text and fonts
- Gradients
- Strokes
- Icons
Each image has simple clear SVG code:
<svg xmlns="http://www.w3.org/2000/svg" width="1080" height="1080" viewBox="0 0 1080 1080">
<rect x="0" y="0" width="100%" height="100%" fill="#ebecec" />
<defs>
<linearGradient id="gradient_9756" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" stop-color="#742a21" />
<stop offset="20.2%" stop-color="#711f39" />
<stop offset="36.6%" stop-color="#4b2d1c" />
<stop offset="37.1%" stop-color="#387d1d" />
<stop offset="60.5%" stop-color="#100f0d" />
<stop offset="100%" stop-color="#ebecec" />
</linearGradient>
</defs>
<rect x="0" y="0" width="1080" height="1080" fill="url(#gradient_9756)" />
</svg>The Core Task: Can an LLM Read and Recreate SVGs?
This benchmark focuses on a seemingly simple but crucial task: taking a rendered SVG and translating it back into valid SVG code. If an AI model can do this well, it’s a strong sign that it has the basic understanding needed to handle more complex design challenges.
Understanding the Scoring Metrics
To evaluate model performance, we use three complementary metrics that together provide a full picture of SVG generation quality:
1. BLEU Score (Code Similarity)
The BLEU score measures how closely the generated SVG code matches the reference code. It captures structural accuracy, penalizes missing or extra elements, and ensures correct syntax.
- 0.7–1.0: Near-perfect reproduction
- 0.4–0.7: Good structural match with minor variations
- 0.0–0.4: Significant code differences
Limitations: BLEU is sensitive to code formatting and attribute order, and it may not recognize visually identical but structurally different SVGs.
2. Structural Similarity (SSIM)
SSIM measures how similar the rendered images are, focusing on:
- Luminance: Brightness levels
- Contrast: Light and dark variations
- Structure: Spatial relationships between elements
- 0.95–1.00: Visually identical
- 0.80–0.95: Minor visual differences
- Below 0.80: Noticeable discrepancies
SSIM aligns well with human perception, making it a strong indicator of visual correctness.
3. Pixel-wise Similarity
This metric directly compares rendered pixels to detect differences.
- 1.0: Perfect match
- 0.9–1.0: Nearly identical
- Below 0.9: Significant pixel variations
Pixel-wise similarity is crucial for catching subtle rendering artifacts and ensuring exact visual reproduction.
How These Metrics Work Together
Each metric provides unique insights:
- High BLEU, Low SSIM/Pixel: The code is structured correctly, but the visual output differs (e.g., wrong colors or coordinates).
- Low BLEU, High SSIM/Pixel: Different code produces the same visual output (e.g., different SVG elements achieving the same look).
- High SSIM, Low Pixel: Small rendering variations exist (e.g., anti-aliasing or minor positioning errors).
By considering all three, we get a well-rounded assessment of how well a model understands and reproduces SVG graphics.
How Do Models Perform on This?
We ran a bunch of models through the benchmark, and the results were striking. Some models performed reasonably well in specific areas, while others struggled across the board.
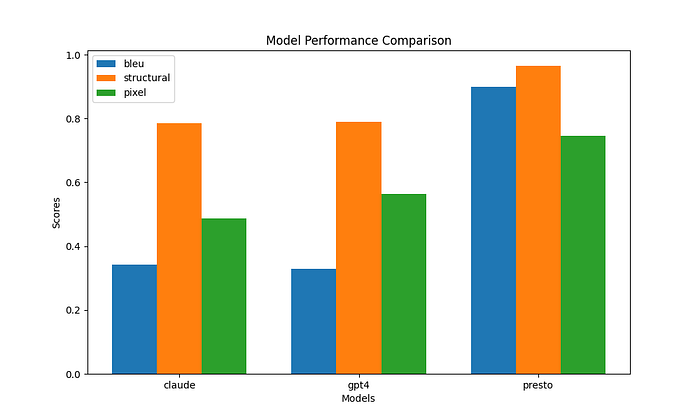
Presto vs. The Competition: A Huge Gap
Our model, built specifically for SVG and graphic design tasks, significantly outperforms general-purpose models like Claude and GPT-4. Across all three evaluation metrics — BLEU, Structural Similarity (SSIM), and Pixel Similarity — Presto demonstrates clear superiority.

Rendering success
This measures if the output of the model could be rendered by CairoSVG, a standard SVG renderer
- Presto achieved a perfect success rate with no generation or rendering failures
- Both Claude and GPT-4 had 2 generation failures each (93.8% success rate)
BLEU Scores (Code Accuracy)
- Presto significantly outperformed with a near-perfect BLEU score of 0.899
- Claude and GPT-4 showed similar performance around 0.35–0.36
- This indicates Presto generates much more accurate SVG code
Presto achieves a much higher BLEU score, indicating that its generated SVG code closely matches the original.
Structural Similarity (Visual Accuracy)
All models achieved good structural similarity (SSIM)
- Presto led with 0.965, indicating near-identical visual output
- laude and GPT-4 performed similarly (~0.84), showing good but visibly different results
Presto’s near-perfect SSIM score suggests that its generated images look almost identical to the references, while the other models introduce distortions.
Pixel Similarity (Rendering Fidelity)
Pixel-wise similarity scores were lower across all models given the challenge of exact pixel precision.
- Presto achieved the highest at 0.745
- GPT-4 (0.600) performed better than Claude (0.518) on exact pixel matching
Why Do These Differences Matter?
The results demonstrate a clear performance gap between Presto and current general-purpose LLMs (Claude and GPT-4) in SVG generation tasks. While all models showed competence in maintaining structural similarity, Presto’s superior BLEU scores (0.899 vs ~0.35) indicate it produces significantly more accurate and maintainable SVG code.
This advantage extends to both visual fidelity (0.965 SSIM) and technical precision (0.745 pixel similarity).
The perfect success rate of Presto, compared to the 93.8% of other models, further establishes it as a more reliable solution for production SVG generation tasks where consistency and accuracy are crucial.
Key Takeaways
- Presto achieves near-perfect accuracy in many fundamental SVG tasks.
- Claude and GPT-4 struggle with object positioning, fonts, and color consistency.
- The best-performing competitor models still produce errors in complex elements like gradients and masks.
Want to Help Improve AI Design?
This is just the beginning. We’d love for others to jump in — train new models, improve evaluation methods, or just test things out.
Also, check out our article: Why LLMs Are Bad at Creating SVGs and Graphic Design — And How to Make Them Good for a deep dive into the challenges and what we can do about them.
By putting this benchmark out there, we hope to spark more progress in AI-driven design. Because at the end of the day, we all want a world that looks better, feels more creative, and isn’t just dominated by walls of text.
