How does OpenAI o1 🍓 work?
This week, OpenAI stunned the world once again by releasing an AI model that delivers a new high point on intelligence benchmarks.
The world is hungrily racing towards the next milestone in artificial intelligence, systems that can act as agents not just clever conversationalists.
Applying current models to agentic frameworks quickly leads to sadness: Agents spin their wheels, running down rabbit holes and losing sight of their goal. After many attempts by the intrepid developer to put guardrails around the agent, the human eventually throws their hands in the air in hopeless defeat.

OpenAI’s o1 “strawberry” provides meaningful progress towards an agent capable model (it may even count as one in some’s definitions). It can hold onto a goal for a much longer time horizon than GPT 4o generation models, although still notably gets distracted in long enough conversations and in complicated situations.
As many AI labs, squeezed by high capital demands, commercial pressures, regulatory scrutiny and international safety concerns, move towards closed research, it provides the rest of us with an intriguing series of mysteries, the jewels of intelligence working in plain sight begging to be unravelled.
This post is my uneducated outsider guesses and opinions; the best i can hope for is to be pointing in the right direction. Training a frontier level model has increasingly become a huge undertaking (Meta’s paper about the work that went into Llama 3.1 is a great inventory of all the labor and computation required) and undoubtedly many more steps and tricks went into o1 than I will think to list here.
The evolution towards silent thinking
Early in the Cambrian-explosion of LLMs it was discovered that chain-of-thought significantly improves their ability to solve problems. This is beneficial for all the same reasons we train high-school students in Math class to write out their reasoning: we rarely can jump to the conclusion to a difficult problem after first reading of the question.

This is true for LLMs for the same reason it’s true for humans: In thinking or speaking, our next phoneme comes from a fixed and insufficient computation budget. There is a fixed depth to our language generation ability, in proportion to the structure of our brain (specifically, the part dedicated to generating language). This same fixed budget is nakedly clear in the architecture diagram of an LLM: the number of layers of the the transfer, the number of attention heads and the width of the vector bandwidth running up though this is a hard limit on how much the information can be transformed into the next token.
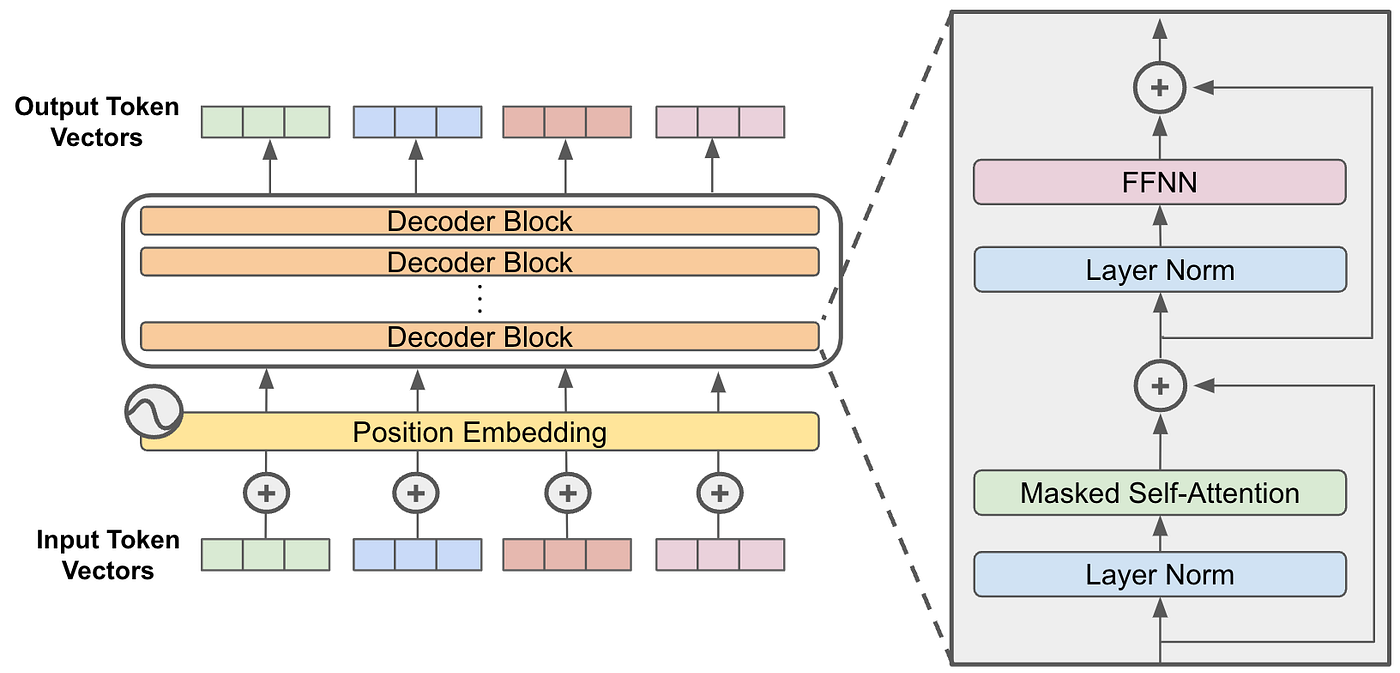
Writing down your working steps, thinking out loud, talking through the problem, rubber ducking, journalling, thinking to yourself on silent walks are all the same essential trick: generate more tokens to give room for serial computation. Every subsequent token linearly increases the total available computation available.
Chain of thought reasoning has been so successful that all frontier models employ it extensively:
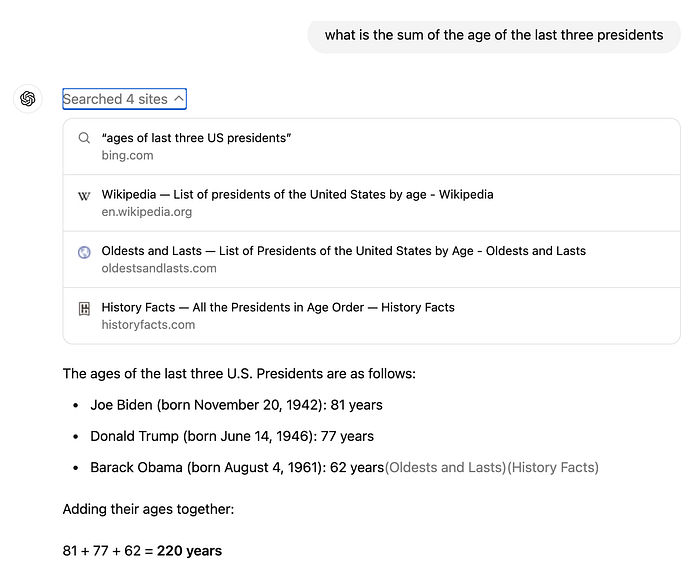
We’re now trained to pop in the question, watch a wall of text zoom by, scroll to the end and read the question. A very logical next UI development is to let the model talk to itself and offer the user brevity.
On similar human tracks, to solve even more complicated problems, we teach university students to create a research plan. Outline the sub-problems to be tackled, work though them, then ultimately compose their essay or synopsis. This hierarchical problem solving is fundamental to how society scales its intelligence, from individual problems up to teams, organizations and societies.
GPT 4o level models struggle with hierarchical work for a few reasons.
One major area is that LLMs perform worse as context window grows (see this paper on RAG systems for an overview). An LLM generally scales its architecture linearly O(n) with context window size (e.g. every input token is processed through a replication of the same stack, with attention heads able to look back at every token previous to it — O(n²) operations).
As context windows grow, attention is averaging an increasing number of signals, reducing the ability to precisely recall individual pieces of information.
Furthermore, whilst the stack generating the latest token can lookback to every previous token, its own bandwidth (i.e. the width of the attention heads, the number of layers of re-combination) is fixed, therefore as the context window grows the LLM has a diminishing ratio of compution power to information available.
A third challenge for hierarchical work is that the training of the model simply doesn’t equip it, the training examples in both supervision and alignment historically have contained internet text, and synthesized examples of chain of thought, but no bigger reasoning work.
o1–preview overview
Making bold guesses and predictions publicly rarely leads to vindication. With that caveat, here we go!
Pre-training
the user interface of o1, you can see the following key elements:
- A series of thinking blocks
- Then the final answer
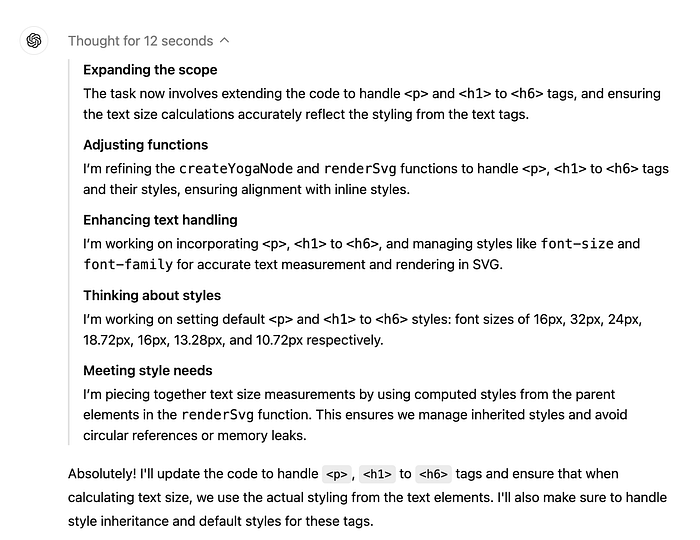
Each thinking block displays to us a title, an animation whilst thinking tokens are consumed, then finally a summary of its thinking. In the o1 release notes there is an illustration of the thinking tokens as being long winded.
Based on all this, we can guess the following parts (in a llama chat template style) have been inserted into the agent response blocks of the chat aligned model:
Ok I’ll help with that!
<|thinking_block|>
<|headline|>How to count letter r in word
<|thoughts|>
Many
many
Many
thinking tokens
<|summary|>You can count letters by listing each letter, then a count of letters so far
<|end_thinking_block|>
Let’s count those letters!
s 0
t 0
r 1
…..
Furthermore, I’m guessing that the tokens after <|thoughts|> get redacted from future generation prompts once the <|end_thinking_block|> has been reached to boost the model by reducing the context window size. This is not neccessary for the overall approach I’ll outline here, as the model could also just learn through training attention to pick out the <|summary|> sections.
Working from a base model (e.g. GPT4o with all of its pre-training on internet content) the next steps are to:
- Use supervised fine tuning to teach the model to work with this thinking structure
- Apply OpenAI’s standard corpus of alignment training under PPO, perhaps translated into this thinking structure via a LLM or masking out the thinking blocks so the gpt4o style data can be applied directly to this new chat modality
- Use reinforcement learning to then boost the model’s performance, backed by this new tool of hierarchical thinking
- Apply OpenAI’s safety alignment under PPO (using similar techniques to 2)
Note that these steps could be performed in various permutations and achieve a successful model, it’s likely my ordering is incorrect.
Supervised fine tuning
To get the model to use the new thinking format, we can cheaply train it under SFT. To do this, we need a big corpus of example dialogues (human question, assistant response) that all leaverage this thinking block structure. This corpus ideally has a good diversity of topics to encourage the model to always use the format.
This step neccessarily carries one challenging burden: the thinking steps, their tokens and conclusions are ideally high quality. The reinforcement learning step later should boost the models harnessing of these, but if the sections were full of junk then the model would never have the predisposition to leaverging the power of hierachical thought.
There are a few major tools for creating this data:
- Have humans generate it (e.g. ask them to solve a problem and write out every step)
- Synthesise the data from deterministic problems (e.g. take machine solvable mathematics/logic/programming/geometric problems and document every single step)
- Use existing LLMs to translate human/machine generated solution steps into this format
- Use existing LLMs to explain their thought on problems they can solve (at least, sometimes solve if we can verify the solution) in this format
Likely a mix of all of the above was used (Meta’s paper lays out similar approach). There is a lot of synergy of using humans to generate the difficult reasoning steps, and using LLMs to do all the mundane data formatting, summarization and translation.
From the performance of o1, it looks like the data used has had some focus on programming and math problems, and possibly also leaveraged existing academic papers as sources of problem solutions. There also might be some representiation of the logic puzzles people like to use to bamboozle LLMs, such as asking it to count letters, or figure out riddles.
Once a good mix of example conversations as been created, the model can be trained using good old fashioned auto-regressive loss. Learn to generate next token, rinse repeat.
It has been noted how today’s large parameter models have ample space to memorize any new data presented under SFT — probably one epoch (e.g. run through the training data) is plenty here.
Reinforcement learning
Alignment training was the crucial breakthrough that propelled GPT3 to world fame. Purely supervised training delivers a model that will competently continue a sentence in a grammatically and thematically valid direction, but it does not deliver a model that follows instructions.
One big reason for this is SFT does not strongly discourage the prediction of tokens (other than pushing down their liklihood of prediction thanks to the softmax output layer), so tokens that are valid speech maintain a fairly high likelihood of being generated despite not being “what we want”. A minor secondary reason is that the major corpus used for pre-training, the public internet, generally lacks examples of user request and AI response.
Alignment training seeks to provide demonstrations of good behavior (e.g. doing what the user asked, not breaking the law), often counter-examples of bad behavior and steer the model towards the former. OpenAI generally seems to prefer using reinforcement learning for this, elsewhere DPO and ORPO are becoming popular due to their stability, effectiveness and efficiency.
Reinforcement learning is strictly more powerful than DPO/ORPO style methods as it has the capacity to inform earlier tokens in the AI’s response of their impact on the correctness of the final answer. This is especially valuable for o1 style reasoning as the full AI responses with thinking tokens are very long (therefore there are many tokens that need to be trained vis-a-vis their downstream impact on the final response), and it also allows to train the model under game-playing (as opposed to only training it on pre-generated examples of good and bad responses).
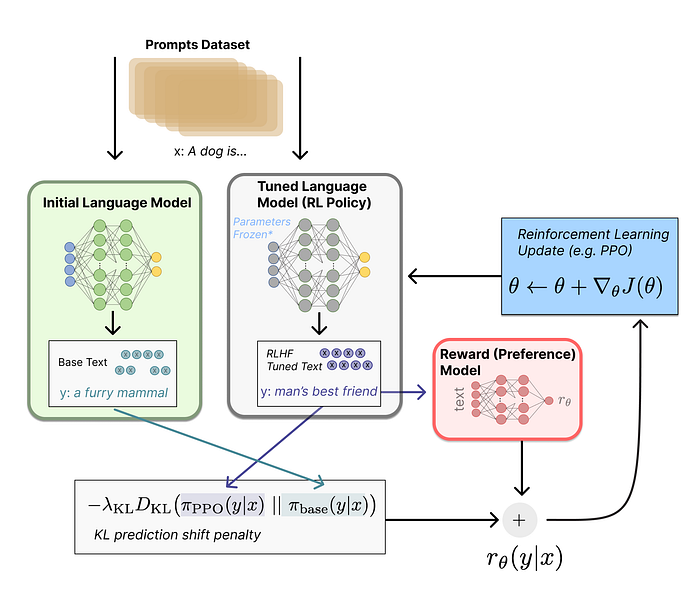
To train an RL system, we need a problem domain where a reward signal (e.g. score) is either in the dataset, or can be computed for each response. Mathematics and programming (o1-preview’s seeming strong suit) are exactly these sort of domains: you can compute mathematical formulas, verify reasoning chains. Similarly, programming often affords being able to run code to see if it outputs the correct answer.
In RL you train a reward function to predict the eventual score of the LLM’s response based on the generation so far. This is used to then train the LLM whether those were good token choices.
For training a reward function, mathematics has another nice property: the interim steps are verifiable and linearly contribute to the final correctness. One broken step of reasoning invalidates the final response (ignoring a later mistake that proces to be a lucky correction). Therefore precise signals of final reward can be learned from the first mistake.

Ilya Sutskever and co published an enlightening paper on exactly this topic: training reward functions on interim reasoning steps in mathematics, based off human generated data. They trained their reward model, and used it to boost token/answer sampling, generating higher performance on mathematic benchmarks
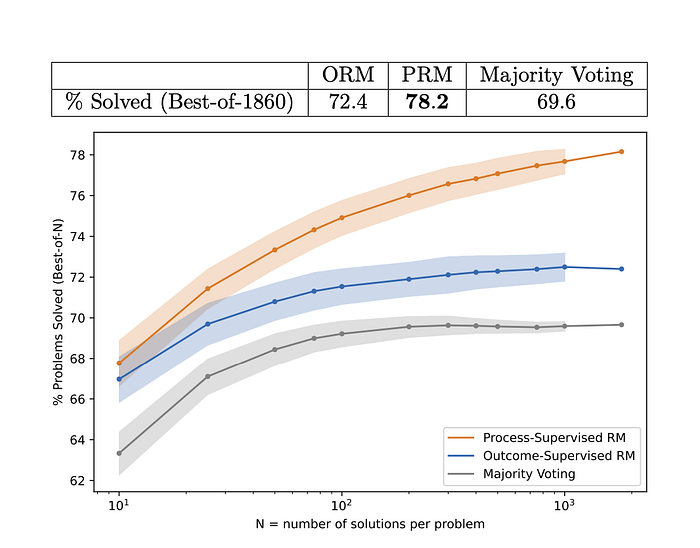
Putting this all together: we can train a reward function on all of the earlier training data for SFT (these being examples of correct reasoning using the thinking blocks), and we can also use both human annotated and machine generated incorect answers to programming/mathematics problems, where the step of reasoning where things fell down is labelled. This is of course easy to say and much harder to build in reality!
Then given this reward function the pre-trained model from earlier can trained against a broad corpus of problems (for which the reward model is capable to estimate final reward). With it’s baked-in inclination to use thinking blocks, and the reward model’s ability to estimate the correctness of those blocks in getting to a correct answer, with sufficient work the RL training process should continually improve the system’s ability to harness thinking blocks to the ceiling of it’s parameter size and the reward model’s competence.
A wonderful property of LLMs is their ability to repurpose their learning to new tasks. By virtue of their sophisticated internal representation and also the learning of serial tasks (such as imitating the example query-response given to a new question), frequent synergies emerge from the diversity of their training data.
Similarly, it appears that o1-preview uses it’s core training to apply hierarchical reasoning to other problem domains, with impressive but lower success than it’s core competencies.
—
This has been a long article to state a small number of hypotheses:
- The model is trained to use thinking blocks
- Mathematics and programming are ameniable domains for generating and scoring reasoing steps in those thinking blocks
- Reinforcement learning is a good tool for educating a model how to use its thinking blocks
With so much exposition and conjecture, I very much look forward to discussion and corrections!
